Region Failover
Region Failover 提供了在不丢失数据的情况下从 Region 故障中恢复的能力。这是通过 Region 迁移 实现的。
开启 Region Failover
该功能仅在 GreptimeDB 集群模式下可用,并且需要满足以下条件
- 使用 Kafka WAL
- 使用共享存储 (例如:AWS S3)
通过配置文件
在 metasrv 配置文件中设置 enable_region_failover=true.
通过 GreptimeDB Operator
通过设置 meta.enableRegionFailover=true, 例如
helm install greptimedb greptime/greptimedb-cluster \
--set meta.enableRegionFailover=true \
...
Region Failover 的恢复用时
Region Failover 的恢复时间取决于:
- 每个 Topic 的 region 数量
- Kafka 集群的读取吞吐性能
读放大
在最佳实践中,Kafka 集群所支持的 topics/partitions 数量是有限的(超过这个数量可能会导致 Kafka 集群性能下降)。 因此,GreptimeDB 允许多个 regions 共享一个 topic 作为 WAL,然而这可能会带来读放大的问题。
属于特定 Region 的数据由数据文件和 WAL 中的数据(通常为 WAL[LastCheckpoint...Latest])组成。特定 Region 的 failover 只需要读取该 Region 的 WAL 数据以重建内存状态,这被称为 Region 重放(region replaying)。然而,如果多个 Region 共享一个 Topic,则从 Topic 重放特定 Region 的数据需要过滤掉不相关的数据(即其他 Region 的数据)。这意味着从 Topic 重放特定 Region 的数据需要读取比该 Region 实际 WAL 数据大小更多的数据,这种现象被称为读取放大(read amplification)。
尽管多个 Region 共享同一个 Topic,可以让 Datanode 支持更多的 Region,但这种方法的代价是在 Region 重放过程中产生读取放大。
例如,为 metasrv 配置 128 个 Topic,如果整个集群包含 1024 个 Region(物理 Region),那么每 8 个 Region 将共享一个 Topic。
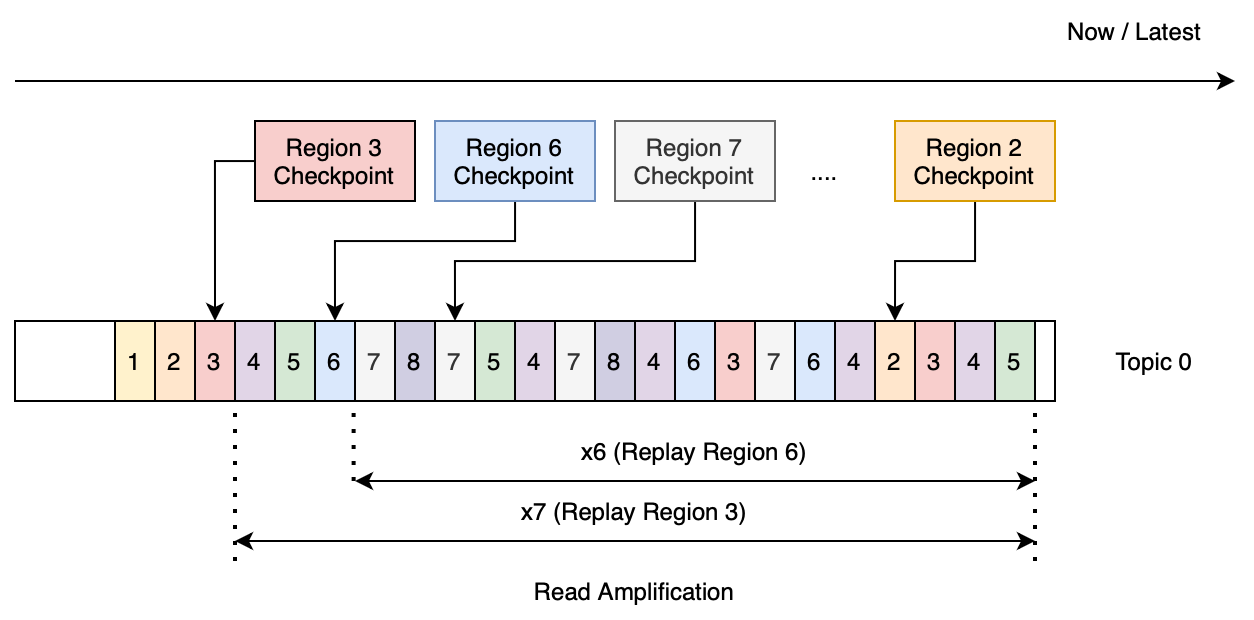
(图 1:恢复 Region 3 需要读取比实际大小大 7 倍的冗余数据)
估算读取放大倍数(重放数据大小/实际数据大小)的简单模型:
- 对于单个 Topic,如果我们尝试重放属于该 Topic 的所有 Region,那么放大倍数将是 7+6+...+1 = 28 倍。(图 1 显示了 Region WAL 数据分布。重放 Region 3 将读取约为实际大小 7 倍的数据;重放 Region 6 将读取约为实际大小 6 倍的数据,以此类推)
- 在恢复 100 个 Region 时(需要大约 13 个 Topic),放大倍数大约为 28 * 13 = 364 倍。
假设要恢复 100 个 Region,所有 Region 的实际数据大小是 0.5 GB,下表根据每个 Topic 的 Region 数量展示了数据重放的总量。
| 每个 Topic 的 Region 数量 | 100 个 Region 所需 Topic 数量 | 单个 Topic 读放大系数 | 总读放大系数 | 重放数据大小(GB) |
|---|---|---|---|---|
| 1 | 100 | 0 | 0 | 0.5 |
| 2 | 50 | 1 | 50 | 25.5 |
| 4 | 25 | 6 | 150 | 75.5 |
| 8 | 13 | 28 | 364 | 182.5 |
| 16 | 7 | 120 | 840 | 420.5 |
下表展示了在 Kafka 集群在不同读取吞吐量情况下,100 个 region 的恢复时间。例如在提供 300MB/s 的读取吞吐量的情况下,恢复 100 个 Region 大约需要 10 分钟(182.5GB/0.3GB = 10 分钟)。
| 每个主题的区域数 | 重放数据大小(GB) | Kafka 吞吐量 300MB/s- 恢复时间(秒) | Kafka 吞吐量 1000MB/s- 恢复时间(秒) |
|---|---|---|---|
| 1 | 0.5 | 2 | 1 |
| 2 | 25.5 | 85 | 26 |
| 4 | 75.5 | 252 | 76 |
| 8 | 182.5 | 608 | 183 |
| 16 | 420.5 | 1402 | 421 |
改进恢复时间的建议
在上文中我们根据不同的每个 Topic 包含的 Region 数量计算了恢复时间以供参考。 在实际场景中,读取放大的现象可能会比这个模型更为严重。 如果您对恢复时间非常敏感,我们建议每个 Region 都有自己的 Topic(即,每个 Topic 包含的 Region 数量为 1)。